Embeddings Model API
嵌入(Embeddings)是文本、图像或视频的数值表示,用于捕捉输入之间的关系。
嵌入的工作原理是将文本、图像和视频转换为浮点数数组,即向量(vectors)。这些向量旨在捕捉文本、图像和视频的语义意义。向量数组的长度称为向量的维度(dimensionality)。
通过计算两段文本向量表示之间的数值距离,应用程序可以判断用于生成这些向量的对象之间的相似度。
EmbeddingModel 接口旨在方便地与 AI 和机器学习中的嵌入模型集成。它的主要功能是将文本转换为数值向量,通常称为嵌入(embeddings)。这些嵌入在语义分析、文本分类等各种任务中起着关键作用。
EmbeddingModel 接口的设计围绕两个核心目标:
- 可移植性(Portability):该接口确保在各种嵌入模型之间能够轻松适配。开发者可以在不同的嵌入技术或模型之间切换,而只需做最少的代码修改。这一设计理念与 Spring 的模块化和可互换性理念保持一致。
- 简洁性(Simplicity):
EmbeddingModel简化了文本到嵌入的转换过程。通过提供像embed(String text)和embed(Document document)这样直观的方法,它将处理原始文本数据和嵌入算法的复杂性隐藏起来。这一设计使开发者,尤其是 AI 初学者,能够在不深入底层机制的情况下轻松在应用中使用嵌入。
API 概览
嵌入模型(Embedding Model)API 构建在通用的 Spring AI 模型 API 之上,后者是 Spring AI 库的一部分。因此,EmbeddingModel 接口继承自 Model 接口,Model 接口提供了一套与 AI 模型交互的标准方法。EmbeddingRequest 和 EmbeddingResponse 类分别继承自 ModelRequest 和 ModelResponse,用于封装嵌入模型的输入和输出。
嵌入 API 则被更高层的组件所使用,用于针对特定的嵌入模型(如 OpenAI、Titan、Azure OpenAI、Ollie 等)实现嵌入模型功能。
下图展示了嵌入 API 及其与 Spring AI 模型 API 以及各嵌入模型之间的关系:
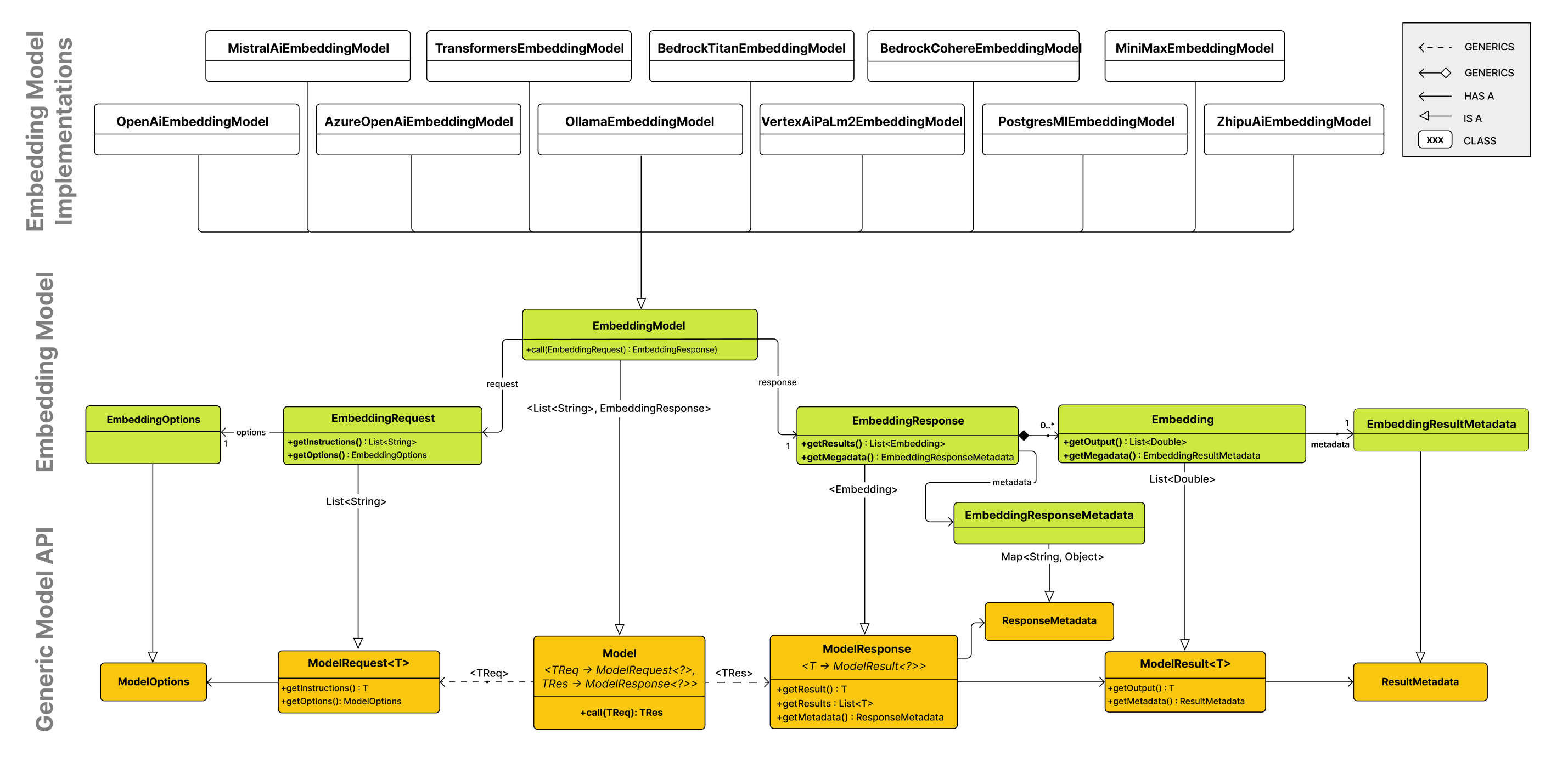
EmbeddingModel
本节提供了对 EmbeddingModel 接口及相关类的使用指南。
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> {
@Override
EmbeddingResponse call(EmbeddingRequest request);
/**
* 将给定文档的内容转换为向量。
* @param document 要嵌入的文档
* @return 嵌入向量
*/
float[] embed(Document document);
/**
* 将给定文本转换为向量。
* @param text 要嵌入的文本
* @return 嵌入向量
*/
default float[] embed(String text) {
Assert.notNull(text, "Text must not be null");
return this.embed(List.of(text)).iterator().next();
}
/**
* 将一批文本转换为向量。
* @param texts 文本列表
* @return 嵌入向量列表
*/
default List<float[]> embed(List<String> texts) {
Assert.notNull(texts, "Texts must not be null");
return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY))
.getResults()
.stream()
.map(Embedding::getOutput)
.toList();
}
/**
* 将一批文本转换为向量并返回 {@link EmbeddingResponse}。
* @param texts 文本列表
* @return 嵌入响应
*/
default EmbeddingResponse embedForResponse(List<String> texts) {
Assert.notNull(texts, "Texts must not be null");
return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY));
}
/**
* @return 嵌入向量的维度数量,与具体生成模型相关
*/
default int dimensions() {
return embed("Test String").length;
}
}
embed 系列方法提供了多种将文本转换为嵌入的选项,可处理单个字符串、结构化的 Document 对象,或文本批量处理。
为了方便使用,还提供了多种快捷方法,例如 embed(String text),它接收单个字符串并返回对应的嵌入向量。所有快捷方法都是基于 call 方法实现的,而 call 方法是调用嵌入模型的核心入口。
通常,嵌入结果以浮点数列表的形式返回,表示数值向量。
embedForResponse 方法则提供了更完整的输出,可能包含嵌入向量的附加信息。
dimensions 方法是开发者快速获取嵌入向量维度的便捷工具,这对于理解嵌入空间及后续处理步骤非常重要。
EmbeddingRequest
EmbeddingRequest 是 ModelRequest 的实现,用于封装文本列表及可选的嵌入请求参数。简化版本如下(省略构造方法和其他工具方法):
public class EmbeddingRequest implements ModelRequest<List<String>> {
private final List<String> inputs;
private final EmbeddingOptions options;
// 其他方法省略
}
EmbeddingResponse
EmbeddingResponse 用于封装 AI 模型的输出,其结构如下:
public class EmbeddingResponse implements ModelResponse<Embedding> {
private List<Embedding> embeddings;
private EmbeddingResponseMetadata metadata = new EmbeddingResponseMetadata();
// 其他方法省略
}
embeddings列表中每个Embedding实例包含单条文本输入的向量结果。metadata提供 AI 模型响应的附加信息。
Embedding
Embedding 表示单个嵌入向量,其结构如下:
public class Embedding implements ModelResult<float[]> {
private float[] embedding;
private Integer index;
private EmbeddingResultMetadata metadata;
// 其他方法省略
}
embedding存储具体的向量数据。index表示输入文本在批量请求中的索引。metadata包含当前嵌入结果的元信息。
可用实现
在内部,各种 EmbeddingModel 实现使用不同的底层库和 API 来执行嵌入任务。以下是一些可用的 EmbeddingModel 实现示例: